Two years ago more or less I started my journey in Linux. I was scared at first and I didn’t know where to start from. But then I decided to buy a book - and what a book! - in order to follow a path.
Along the way, I integrated the material with up-to-date documentation from kernel.org and source code. In the meantime, I started to learn C a bit so that I also could have played with what I was learning, step by step.
One of the things I was fascinated by was how Linux is able to manage and let the CPU run thousands and thousands of processes each second. To give you an idea, right now, Linux on my laptop configured with an Intel i7-1185G7 CPU switched context 28,428 times in a second! That’s fantastic, isn’t it?
$ perf stat -e sched:sched_switch --timeout 1000
Performance counter stats for 'system wide':
28,428 sched:sched_switch
1.001137885 seconds time elapsed
During this journey inside Linux, I’ve written notes as it helps me to digest and re-process in my own way the informations I learn. Then I thought: “Maybe they’re useful to someone. Why not share them?”.
So here I am with with a blog.
1. Resource sharing is the key!
Let’s dive into the Linux component which is responsible for doing such great work: the scheduler.
In order to do it, imagine what we would expect from an operating system. Let’s say that we’d want it to run tasks that we need to complete, providing the OS hardware resources. Tasks come of different natures but we can simply categorize them as CPU-intensive and interactive ones.
Something should provide the efficiency of task completion and responsiveness. Consider a typewriter that prints letters with 1s second of delay, it would be impossible to use! So, in a few words, I would like to request to the scheduler: “I want to execute this task and I want it’s completed when I need or to respond when I need”. The goal of a scheduler is to decide “what runs next” leading to have the best balance between the needings of the different natures of the tasks.
As Linux is a preemptive multitasking operating system, the completely fair scheduler (CFS) came to Linux, as the replacement of the O(1) scheduler from the 2.6.23, with the aim to guarantee the fairness of CPU owning by the tasks, and at the same time tailoring to a broad nature range of tasks. Although the algorithm complexity didn’t see an improvement, from O(1) to O(log N), the reduced latency removed issues when dealing with interactive tasks.
As a side note consider that the Linux scheduler is made of different scheduler classes (code), of which the CFS class is the highest-priority one. Another one is the real-time scheduler class, tailored as the name suggests for tasks that need responsiveness.
Interactive tasks would run for small amounts of time but need to run quickly as events happen. CPU-intensive tasks don’t require to complete ASAP but require longer CPU time. Based on that, time accounting is what guarantees fairness in the Linux CFS scheduler as long as the task that runs for less time will run next.
This comes to the time accounting, so let’s start to dig into it!
2. Time accounting
Linux CFS actually does not directly assign timeslices to tasks as the O(1) scheduler did, instead it measures execution time, in order to be flexible with respect to both interactive and processor-intensive tasks.
The runtime
Remember, the fundamental rule in the Completely Fair Scheduler is: the task that ran less, will run next! Which is, each task should have its fair slice of processor time when it needs! For example, interactive tasks can run frequently but for less time than intensive ones, and still have their fair amount of CPU time.
The implementation is written in the update_curr() function, which is called periodically to account tasks for the CPU time they used in the last period (delta_exec).
The virtual runtime
The execution time is further weighted to implement priority between tasks. This is done by the fair delta calculation. The more the weight, the more time the task will have.
Example
Let' do an example with timeslices: considering a single CPU, if every T time period two tasks A and B run respectively with a weight of 1 and 2, the allocated CPU time is obtained by multiplying T by the ratio of the weight to the sum of the weights of all running tasks:
CPU_timeslice(A) = T * (1 / (1 + 2))).
CPU_timeslice(B) = T * (2 / (1 + 2))).
For each T time period, task A will run for 0.334~T and task B 0.667~T.
This is what is calculated here.
Implementation
Coming to the actual implementation, the CFS class accounts tasks for their real execution time considering their weight, which is ensured by periodically measuring the runtime and multiplying it by the ratio weight/(base weight).
runtime += runtime * (w / base w)).
Which is exactly what is done in update_curr():
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
...
delta_exec = now - curr->exec_start;
...
curr->vruntime += calc_delta_fair(delta_exec, curr);
...
}
And the result is the so-called virtual runtime (vruntime).
As the weight implementation depends on the nature of the schedule entities, let’s spend a couple of words about them.
Indeed, the
vruntimeis a member of thesched_entitystructure.
Then, we’ll talk more about the runtime weight.
The schedule entities
Until now we talked about tasks as the only schedulable entity but actually, tasks can be put into group of tasks, in order to treat a group equally to a single task, and have the group share the resources (I.e. CPU) between the entities of the group without afflicting the overall system. That’s the case of cgroups and why they’re there.
Also, task groups can be composed of other groups, and there is a root group. In the end, a running Linux is likely going to manage a hierarchy tree of schedule entities. So when a task should be accounted for time, also the parent group’s entity should be, and so on, until the root group entity is found.
Consider that the
sched_entitystructure is the structure that tracks information about the scheduling, like thevruntime, and it refers to tasks or tasks group structures. As they track scheduling data, they are per-CPU structures. Instead,task_structandtask_groupstructures, are global.
And this comes to the weight.
The weight
We said before that the weight implementation depends on the nature of the entity. If the entity is a task the weight is represented by the niceness value (code). If it’s a task group, the weight is represented by the CPU shares value.
In cgroup v2 the
sharesis named directlyweight.
In the end, the weight is what matters: in the case of tasks the niceness is converted to priority and then to weight (here). In the case of task groups the user-visible value is internally converted.
For the sake of simplicity let’s remember this: the groups are hierarchical, and a task is part of a task group. The bigger the depth of the hierarchy, the more the weight gets diluted. Adding a heavily weighted task to one child group is not going to afflict the overall tasks tree the same as it would do if it was part of the root group. This is because the task weight is relative to the group which the task is put into.
Each entity, whether a task or a task group, is treated the same. The time accounting is applied to the currently locally running entity and recursively up through the hierarchy.
In case of task groups, the weight is further scaled, but don’t worry, we’ll talk about it later.
Update of the virtual runtime
This virtual runtime is updated on the schedule entity that is currently running on the local CPU via update_curr() function, which is called:
- whenever a task becomes runnable, or
- whenever blocks become unrunnable, and
- periodically (every 1/
CONFIG_HZseconds) by the system timer interrupt handler.
As a detail, the virtual runtime value if the task is just forked, is initialized to a minimum value which depends on the runqueue load (
cfs_rq->min_vruntime).
And this leads to the next question: how this accounting is honored in the task selection in the scheduler in order to guarantee fairness of execution?
3. Task selection
The schedule entities eligible to run (which is in a runnable state) are put in a run queue, which is implemented as a red black self-balancing binary tree that contains schedule entity structures ordered by vruntime.
The runqueues
Runqueues are per-CPU structures and contain schedule entities and they have a pointer to the entity which is currently running on the related CPU. The schedule entities they refer to are related to the local CPU because the sched_entitys contain information about scheduling and thus are specific to a CPU. The vruntime is the binary tree key so the entity with the smallest vruntime is picked during a new schedule.
Each scheduler class has its specific runqueue, which are part of the general runqueues. Anyway, let’s consider now only CFS runqueues.
In turn, also each task group has a dedicated CFS runqueue, from the root task group through its child task groups. __pick_next_entity() picks the entity with the smallest virtual runtime, whether is an actual task or a group. If it’s a task group the search is repeated on its runqueue and so on, going through the hierarchy of runqueues until a real task is found to be run.
Each runqueue keeps track of the schedule entities that are running/runnable on the local CPU.
In a nutshell
- Tasks groups are global.
- Tasks also are global.
- Every task is part of a task group.
- There is one runqueue per task group per CPU.
- Runqueues are composed of schedule entities.
- Schedule entities reference tasks or task groups.
- Schedule entities are per CPU
Wrapping up the structures
To make it more clear, let’s see a practical example.
You can see below a diagram for a sample scenario where there are two tasks (p1 and p2), and two task groups (root task group and tg1, child of the root task group). And p1 is direct child of task group tg1 and p2 is direct child of the root task group. i is the i-th CPU:
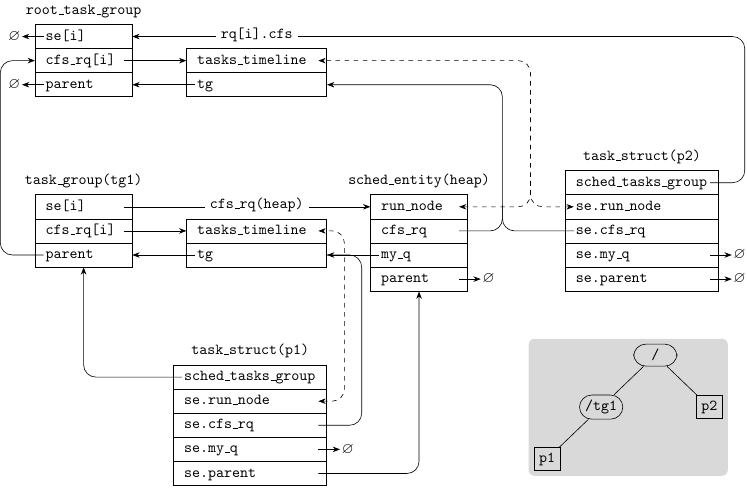
Global structures
task_group.se:se[i]is the task groups’ssched_entitydata for i-th CPU.task_group.cfs_rq:cfs_rq[i]is the task group’scfs_rqdata for i-th CPU.task_group.parent: the parent task group.task_group.shares: the task groupcpu.sharestask_struct.sched_class: the scheduler class the tasks should be scheduled with.
Per-CPU structures
sched_entity.vruntime: the virtual runtime.sched_entity.parent: the schedule entity of the parent task group.sched_entity.my_q: when not a task (NULL), the task group’s CFS runqueue on the local CPU.sched_entity.run_node: the related red-black tree node on the runqueue tree.sched_entity.cfs_rq: the CFS runqueue that manages the schedule entitysched_entity.load: the weight of the entity. If it relates to a task group, is the sum of the weights of the tasks of the group, on the local CPU.cfs_rq.load: the load of the runqueue, aka the sum of the weights of the entities that compose it.cfs_rq.current: the schedule entity that is currently running on the local CPU, where a group or a task.cfs_rq.rq: the general CPU runqueue to which the CFS runqueue is attached.cfs_rq.tg: the task group that owns the runqueue, whether the root one or a child.rq.cfs_tasks: the linked list containing the reb-black tree nodes (e.g. here CFS puts the next entity into it).
If you would like to explore the relations between the entities, I recommend this blog.
Now that we introduced runqueues, let’s talk about the further scaling of the runtime weight for task groups schedule entities.
Weight for task groups
As task groups can be run on multiple CPUs doing real multitasking, the weight (i.e. CPU shares) for task group’s runqueue is further updated (scaled) in entity_tick() based on how much the task group is loaded on the local CPU.
The weight is multiplied by the ratio of the load of the task group running on the local CPU (which is the task group’s runqueue) to the global load of the task group.
This ratio tells us how much the task group is loaded on the local CPU.
As a detail, this is done if configured Linux for symmetrical multiprocessor, otherwise the
sharesis not scaled.
In detail, the load is the sum of the weights of the entities that compose the task group or the task group’s runqueue.
shares = shares * (runqueue's load / task group's load)
TL;DR: the ratio is the sum of the weights of the entities that compose the runqueues to the sum of the weights of the entities that compose the task group:
The calculcation is done by the calc_group_shares() function, to get the final value of the task group’s shares that will weight the virtual runtime of the task group schedule entity:
static long calc_group_shares(struct cfs_rq *cfs_rq)
{
long tg_weight, tg_shares, load, shares;
/
struct task_group *tg = cfs_rq->tg;
/*
tg_shares is the task group's CPU shares.
*/
tg_shares = READ_ONCE(tg->shares);
/*
load is the load of the local CFS runqueue which is,
the load of the task group on the local CPU.
*/
load = max(scale_load_down(cfs_rq->load.weight), cfs_rq->avg.load_avg);
/*
tg_weight is the global load of the task group.
*/
tg_weight = atomic_long_read(&tg->load_avg);
/* Ensure tg_weight >= load */
tg_weight -= cfs_rq->tg_load_avg_contrib;
tg_weight += load;
shares = (tg_shares * load);
if (tg_weight)
shares /= tg_weight;
// ...
/*
shares is now the per CPU-scaled task group shares.
*/
return clamp_t(long, shares, MIN_SHARES, tg_shares);
}
This is done to treat fairly also groups among CPUs!
...
shares = (tg_shares * load);
if (tg_weight)
shares /= tg_weight;
...
Consequently, the vruntime is the binary tree key so the entity with the smallest vruntime is picked by __pick_next_entity(), whether is an actual task or a group. If it’s a task group the search is repeated on its runqueue and so on, going through the hierarchy of runqueues until a real task is found to be run.
As a detail, in order to provide efficiency and to not need to traverse the whole tree every time a scheduling is needed, as the element in an ordered red black tree that is leftmost is the element with a minor key value (i.e. the
vruntime) a cache is easily keeped asrb_leftmostvariable in each runqueue structure. And it’s ideally picked bypick_next_entity().
Finally, we can better see the whole picture!
Wrapping up the time accounting
Now that we have the most important concepts in mind about time accounting, considering how the weight is calculated for both tasks and tasks groups schedule entities, which are part of hierarchical tasks groups' runqueues, let’s see how the time accounting is honored during the periodic tick, fired by the timer interrupt:
/*
* Called by the timer interrupt handler every 1/HZ seconds.
*/
scheduler_tick()
/* The local CPU */
-> int cpu = smp_processor_id();
/* The local CPU runqueue */
-> struct rq *rq = cpu_rq(cpu);
/* The local CPU runqueue currently running task */
-> struct task_struct *curr = rq->curr;
/* The current running task's scheduler class' periodic tick function. */
-> curr->sched_class->task_tick(rq, curr)
/* Let's assume the class is CFS. */
-> task_tick_fair()
-> struct sched_entity *se = &curr->se;
/*
* For each schedule entity through parent task groups
* up to the root task group.
*/
-> for_each_sched_entity(se)
/* The runqueue where the entity is placed. */
-> cfs_rq = cfs_rq_of(se);
-> entity_tick(cfs_rq, se)
/*
* Update the virtual runtime for the current running entity
* on the current selected by loop-task group's runqueue.
*/
-> update_curr(cfs_rq)
-> struct sched_entity *curr = cfs_rq->curr;
-> delta_exec = now - curr->exec_start;
-> curr->exec_start = now;
-> curr->vruntime += calc_delta_fair(delta_exec, curr);
/*
* If it's a task group update the shares
* based on its group runqueue,
* which is the group load on the local CPU
*/
-> update_cfs_group(se)
/* The CFS runqueue of the entity, if it's a task group. */
-> struct cfs_rq *gcfs_rq = group_cfs_rq(se);
/* If the entity is a task, skip */
-> if (!gcfs_rq)
-> return;
/*
* Update the CPU shares for the task group entity.
*/
-> shares = calc_group_shares(gcfs_rq);
-> reweight_entity(cfs_rq_of(se), se, shares);
The code has been a bit simplified to show a clearer picture.
So, the next question is: how a runqueue is populated? When a new task is added do a runqueue?
Runqueues population
The runqueues are populated when:
- a
clone()is called, and - a task wakes up after having slept, via
try_to_wake_up()function call
with enqueue_entity().
And the next question is: when a task is removed from the runqueue?
- When a task explicitly
exit()s (e.g. viaexit()libc function) - When a task explicitly or implicitly requests to
sleep()
with dequeue_entity().
In both enqueue and dequeue cases the rb_leftmost cache is updated and replaced with rb_next() result.
Now that we have a runqueue populated, how does the scheduler pick one task from there?
The scheduler entrypoint
schedule() is the main function which (through __schedule), calls pick_next_task that will return the task that ran less.
For the sake of simplicity, let’s assume that the hyperthreading support is not configured.
More on core scheduling here.
__pick_next_task() picks the highest priority scheduler class which returns the higher priority task, by looping through the hierarchy of task groups' runqueues, until a real task is found. Actually, as we said before, the runqueue red-black trees are not traversed on each schedule, instead, in the end, it picks the rb_leftmost entity rb node, through __pick_next_entity.
schedule() loops while the currently running task should be rescheduled, which is, is no longer fair to be run.
The path is a bit different when the core scheduling feature is enabled.
Then, __schedule() calls context_switch() that switches to the returned task.
And this comes to one of the next topics: context switch. But before talking about that let’s continue talking about the life of a task.
Let’s imagine that we are in process context and that our task is now running. Not all tasks complete from the time have being scheduled. For example, tasks waiting for events (like for keyboard input or for file I/O) can be put to sleep, and also are in interruptible / uninterruptible state so they aren’t picked from the runqueue.
4. Sleep and wake up
A task can decide to sleep but something then is needed to wake it up. We should also consider that multiple tasks can wait for some event to occur.
A wait queue of type wait_queue_head is implemented for this purpose as a doubly-linked list of tasks waiting for some events to occur.
It allows tasks to be notified when those events occur by referencing the wait queue, generally from what generates the event itself.
Sleep
A task can put itself to sleep in the kernel similar to what does the wait syscall:
- create a wait queue via the
DECLARE_WAIT_QUEUE_HEAD()macro - add the task itself to it via
add_wait_queue()function call - set its state to interruptible / uninterruptible via
prepare_to_wait(). If the task is set interruptible, signals can wake it up. - call
schedule()which in turn removes the task from the runqueue viadeactivate_task().
/* ‘q’ is the wait queue we wish to sleep on */
DEFINE_WAIT_QUEUE_HEAD(wait);
add_wait_queue(q, &wait);
while (!condition) { /* condition is the event that we are waiting for */
prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE);
...
schedule();
}
It can also do it non voluntarily waiting for semaphores.
As a detail, wait queues have two implementations, the one we mentioned above and the original one (Linux 2.0) which has been kept for simple use cases and is called now simple wait queues (more on the history here).
Wake up
For the sake of simplicity on the path to waking up let’s take the example of the simple wait queue, as the standard wait queue here is more complex than it is in the preparation to wait, and we don’t need to understand it now.
To wake those tasks that are sleeping while waiting for an event here is the flow:
swake_up_all() (which is pretty analogous to the sibling implementation’s wake_up_all()) calls try_to_wake_up() and is there to wake all processes in a wait queue when the associated event occurs.
try_to_wake_up() does the work that consists of:
- set task state to running - and through
ttwu_queue: - calls the
activate_task()function which adds the task to the runqueue viaenqueue_task() - sets
need_reschedflag on the current task if the awakened task has higher priority than the current one (we’ll talk about this flag later) which provokes then aschedule()(and consequent context switch)
swake_up_all() then removes the task from the wait queue.
Signals
Signals, as well, can wake up tasks if they are interruptible.
In this case, the task code itself should then manage the spurious wake-up (example), by checking the event that occurs or managing the signal (e.g. inotify does it), and call finish_wait to update its state and remove itself from the wait queue.
Completing the sample code above by managing also the waking up part it will end up with something like this:
/* ‘q’ is the wait queue we wish to sleep on */
DEFINE_WAIT_QUEUE_HEAD(wait);
add_wait_queue(q, &wait);
while (!condition) { /* condition is the event that we are waiting for */
prepare_to_wait(&q, &wait, TASK_INTERRUPTIBLE);
if (signal_pending(current))
/* handle signal */
schedule();
}
finish_wait(&q, &wait);
As a detail, wake up can be provoked in both process context and interrupt context, during an interrupt handler execution, which is what often device drivers do. Sleep can be only done in process context.
5. Context switch and Preemption
And this comes to the context switch.
For example, when a task starts to sleep a context switch is needed, and the next task is voluntarily picked and the scheduling is done via schedule().
The context switch work is done by context_switch(), called by the internal __schedule() and executes:
switch_mm()(implementation here for x86) to switch virtual memory mappings process-specific.switch_to()(x86_64) to save and restore stack information and all registers which contain process-specific data.
As you saw, both functions are architecture-dependent (ASM) code. The context switch is requested by the tasks themselves voluntarily or by the scheduler, nonvoluntarily from the point of view of a task.
Voluntary
As we saw tasks can trigger context switch via schedule() in kernel space, either when they explicitly request it or when they put themselves to sleep or they try to wake up other ones. Also, context switch happens when tasks block, for example when synchronizing with semaphores or mutexes.
Anyway, context switches are not done only when code in kernel space voluntarily calls schedule(), otherwise, tasks could monopolize a CPU, so an external component should intervene.
Nonvoluntary: preemption
As the main Linux scheduler class is a fair scheduler the fairness must be guaranteed in some way… Ok, but how does it preempt?
For this purpose, a flag named need_reschedule is present in the task_struct’s thread_info flags (i.e. x86) and is set or unset on the current task to notify that it should leave the CPU which in turn, after schedule() call, will switch to another process context.
So, when this flag is set?
- in
scheduler_tick(), which is constantly called by the timer interrupt handler (the architecture-independent part actually), continuously checking and updatingvruntime, balancing the runqueues, it sets the flag when preemption is needed. - in
try_to_wake_up(), when the current task has minor priority than the awakened.
Then, in order to understand when the flag is checked, we can think about when a task preemption is needed and also can be done safely.
In userspace
Returning from kernelspace to userspace is safe to context switch: if it is safe to switch mode and continue executing the current task, it is also safe to pick a new task to execute. Has this userspace task still to run? Maybe it’s no longer fair to run it. This is what happens when from:
return to userspace.
If need_resched is set a schedule is needed, the next entity task is picked, and context switch done.
As a note, consider that both these paths are architecture-dependent, and typically implemented in assembly in entry.S (e.g. x86_64) which, aside from kernel entry code, also contains kernel exit code).
In kernel space
A note deserves to be explained. The kernel is fully preemptive from 2.6 that is, a task can be preempted as long as the kernel is in a safe state.
When preemption can’t be done, locks are in place to mark it, so that a safe state is defined when the kernel doesn’t hold a lock.
Basically, a lock counter preempt_count is added to thread_info flags (x86) to let preempt tasks that are running in kernelspace only when it’s equal to zero.
Upon return from interrupt to kernelspace or from process context during preemption, if need_resched is set and preempt_count == 0 the current task is preempted, otherwise the interrupt returns to the interrupted task.
Also, every time preempt_count is updated and decreased to zero and need_resched is true, preemption is done.
For example, considering the return path from interrupt which is architecture-dependent, the xtensa ISA’s common exception exit path is pretty self-explanatory:
common_exception_return:
...
#ifdef CONFIG_PREEMPTION
6:
_bbci.la4, TIF_NEED_RESCHED, 4f
/* Check current_thread_info->preempt_count */
l32ia4, a2, TI_PRE_COUNT
bneza4, 4f
abi_callpreempt_schedule_irq
j4f
#endif
...
TL;DR About what we said above, you can check the
__schedule()function comments.
Moreover, the kernel is SMP-safe that is, a task can be safely restored in a symmetrical multi-processor.
You can check both preemption config and SMP config (x86) in your running kernel version from procfs:
$ zcat /proc/config.gz | grep "CONFIG_SMP\|CONFIG_PREEMPT" | grep -v "^#"
CONFIG_PREEMPT_BUILD=y
CONFIG_PREEMPT=y
CONFIG_PREEMPT_COUNT=y
CONFIG_PREEMPTION=y
CONFIG_PREEMPT_DYNAMIC=y
CONFIG_PREEMPT_RCU=y
CONFIG_SMP=y
CONFIG_PREEMPT_NOTIFIERS=y
That’s all folks! We’ve arrived to the end of this little journey.
Conclusion
The linked code refers to Linux 5.17.9.
I liked the idea to leave you the choice to dig into each single path the kernel does to manage the tasks scheduling. That’s why I intentionally didn’t include so many snippets, instead providing you the code face of the coin for almost every path we saw, through links to the real Linux code.
What is incredible is that, even if it’s one of the largest OSS projects, you can understand how Linux works and also contribute. That’s why I love open source more every day!
Thank you!
I hope this was interesting for you as it was for me. Please, feel free to reach out!
Links
- https://www.kernel.org/doc/html/v5.17/scheduler/index.html
- https://elixir.bootlin.com/linux/v5.17.9/source
- https://www.amazon.com/Linux-Kernel-Development-Robert-Love/dp/0672329468
- https://mechpen.github.io/posts/2020-04-27-cfs-group/index.html#2.2.-data-structures
- https://josefbacik.github.io/kernel/scheduler/2017/07/14/scheduler-basics.html
- https://opensource.com/article/19/2/fair-scheduling-linux
- https://lwn.net/Articles/531853/
- https://oska874.gitbooks.io/process-scheduling-in-linux/content/